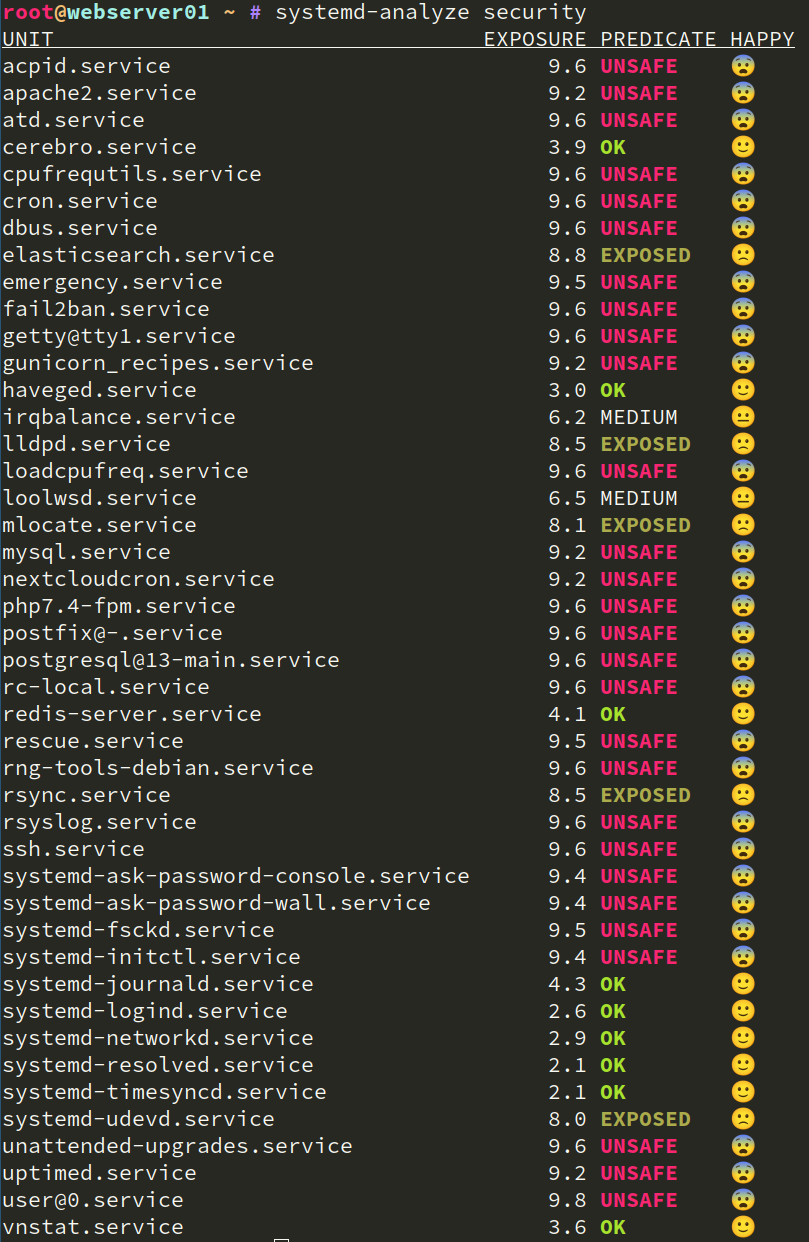
The control repository in a Puppet context is usually a git repository that contains your Puppetfile. The Puppetfile has links to all modules in your environment and their version that shall be deployed. Besides the Puppetfile, Hiera data is often in that repository as well.
Very often people beginn with Puppet by using `puppet apply`. This means they have a bit of Puppet code in a local file and directly apply it. There is no agent running, there is no remote Puppetserver that compiles the catalog. This is easy for beginners but over time tricky to maintain. And eventually most people switch to puppet agent/server setup. By using a simple control repository layout from the beginning, it’s easy to work with puppet apply and an agent/server setup with the same codebase:
.
├── bin
│ └── config_script.sh
├── data
│ └── nodes
│ ├── basteles-bastelknecht.bastelfreak.org.yaml
│ ├── dns02.bastelfreak.org.yaml
│ └── server.fritz.box.yaml
├── environment.conf
├── hiera.yaml
├── LICENSE
├── manifests
│ └── site.pp
├── Puppetfile
├── README.md
└── site
└── profiles
├── files
│ └── configs
│ └── facter.conf
├── Gemfile
├── Gemfile.lock
├── manifests
│ ├── archlinux.pp
│ ├── base.pp
│ ├── centos.pp
│ ├── choria.pp
│ ├── dbbackup.pp
│ ├── debian.pp
│ └── sysctl.pp
├── metadata.json
├── Rakefile
└── templates
└── configs
├── bird.conf.epp
└── ibgp.epp
This is a trimmed down version of my control repository. I will explain the important pieces and how to use it:
bin/config_script.sh
While applying code or compiling a catalog, puppet can execute a script and use the output to version the catalog/code. My script looks like this:
#!/bin/bash
CODEDIR='/etc/puppetlabs/code' # better: $(puppet master --configprint codedir)
CODESTAGEDIR='/etc/puppetlabs/code-staging' # better: "($puppet master --configprint codedir)-staging"
if [ -x /usr/bin/git ]; then
if [ -d $CODESTAGEDIR ]; then
ENVGITDIR="${CODESTAGEDIR}/environments/$1/.git"
else
ENVGITDIR="${CODEDIR}/environments/$1/.git"
fi
/usr/bin/git --git-dir $ENVGITDIR log --pretty=format:"%h - %an, %ad : %s" -1
else
echo "no git - environment $1"
fi
exit 0
The script isn’t required, but it’s helpful to debug your code because it provides information about the version of the code that gets applied.
manifests/site.pp
# include OS specific profiles
case $facts['os']['name'] {
'Archlinux': { contain profiles::archlinux }
'CentOS': { contain profiles::centos }
'Debian': { contain profiles::debian }
default: {}
}
# include base profile that every node gets
contain profiles::base
## pluginsync
file { $::settings::libdir:
ensure => directory,
source => 'puppet:///plugins',
recurse => true,
purge => true,
backup => false,
noop => false
}
# include node specific profiles
lookup('classes', Array[String[1]], 'unique', []).each |$c| {
contain $c
}
Here happens the magic! In a small environment, where people might use puppet apply (like I do for my personal systems), you might have a few operatingsystems. That’s why I have a case statement to load profiles based on the operating system. I also have a base class that every system must have, so I contain that without any conditions. Many Puppet modules ship custom types/providers. They usually don’t work with puppet apply. With the file resource all plugins (types and providers, custom facts…) are copied into the correct directory. This is what happends during a pluginsync during an agent run. At the end I include all classes that are defined in Hiera.
hiera.yaml
---
version: 5
defaults: # Used for any hierarchy level that omits these keys.
datadir: data # This path is relative to hiera.yaml's directory.
data_hash: yaml_data # Use the built-in YAML backend.
# we can't use $trusted because those facts are only available when a puppetserver compiles a catalog
# don't use trusted.fqdn because legacy facts aren't enabled
hierarchy:
- name: "Per-node data" # Human-readable name.
path: "nodes/%{facts.networking.fqdn}.yaml" # File path, relative to datadir.
- name: common
path: common.yaml
The Hiera hierarchy is quite simple. We have one data/common.yaml for defaults and node specific stuff in data/nodes/. This is the recommended minimal setup. You can introduce more hierarchies depending on your infrastructure. Common values are:
- Location (Country, Datacenter)
- Operating System (Family/Name/Major version)
- App environment (staging, development, production)
data/nodes/dns02.bastelfreak.org.yaml
---
classes:
- profiles::choria
profiles::base::borg_keep_monthly: 6
profiles::base::borg_keep_weekly: 12
profiles::base::borg_keep_daily: 14
profiles::base::borg_keep_within: 7
profiles::base::manage_ferm: false
profiles::base::dns_resolvers:
- 127.0.0.1
profiles::archlinux::locales:
- en_US.UTF-8 UTF-8
- en_GB.UTF-8 UTF-8
This is an example for assigning additional profiles. The YAML file contains an array, named classes. the code in the site.pp will look that up and contain every profile listed here
environment.conf
config_version = 'bin/config_script.sh $environment'
modulepath = site:modules:$basemodulepath
This short snippet is quite important as it manipulates the default modulepath. It allows us keep our own puppet code (custom modules, profiles) in the same git repository. Each module is a directory below site/. Alos the config_script.sh is configured here.
Actually use this
So how do we use this? I recommend:
puppet apply /etc/puppetlabs/code/environments/production/manifests/site.pp --show_diff --environment production --write-catalog-summary --summarize --strict_variables --strict error --graph
There are a lot of parameters. This basically tells Puppet to apply the site.pp. This will trigger a hiera lookup and also apply the additional profiles. The remaining parameters, except for –environment, are not required, but helpful.
- –graph render .dot files for all resources and their dependencies to /opt/puppetlabs/puppet/cache/state/graphs/
- –strict / –strict_variables. Handle uninitialized variables as compile error. This is helpful to ensure a clean codebase
- –show_diff when files are updated, print a diff
- –write-catalog-summary create /opt/puppetlabs/puppet/cache/state/*yaml with information about the apply runtime and their resources
- –summarize print some statistics (also contains the output from config_script.sh at the bottom):
root@dns02 ~ # puppet apply /etc/puppetlabs/code/environments/production/manifests/site.pp --show_diff --environment production --write-catalog-summary --summarize --strict_variables --strict error --graph --noop
Notice: Compiled catalog for dns02.bastelfreak.de in environment production in 0.93 seconds
Notice: Applied catalog in 3.67 seconds
Application:
Initial environment: production
Converged environment: production
Run mode: user
Changes:
Events:
Resources:
Total: 743
Time:
Concat fragment: 0.00
Concat file: 0.00
Schedule: 0.00
User: 0.00
Mount: 0.00
Ssh authorized key: 0.00
Exec: 0.00
Cron: 0.00
Pam: 0.00
Ini setting: 0.01
Shellvar: 0.06
Sysctl: 0.09
Package: 0.19
File: 0.19
Service: 0.28
Config retrieval: 1.19
Vcsrepo: 1.52
Last run: 1641152972
Transaction evaluation: 3.60
Catalog application: 3.67
Filebucket: 0.00
Total: 3.70
Version:
Config: 40cc184 - Tim Meusel, Mon Dec 20 15:43:45 2021 +0100 : Merge pull request #68 from bastelfreak/server
Puppet: 7.13.1
root@dns02 ~ #
Conclusion
I really like this code setup because it’s easy to use and hopefully not too opinionated. I’ve used this in a few environments and it works like a charm for puppet apply setups but also for agent/server environments.